
最近,阿里巴巴前副总裁兼首席AI科学家、知名AI框架师贾扬清发朋友圈,爆锤国内某大厂,称其大模型是套壳Meta的LLaMA,即著名的羊驼。概括一下就是说:你要改名就改吧,但别玩掩耳盗铃的花样,免得其他小公司做一堆多余的适配工作……
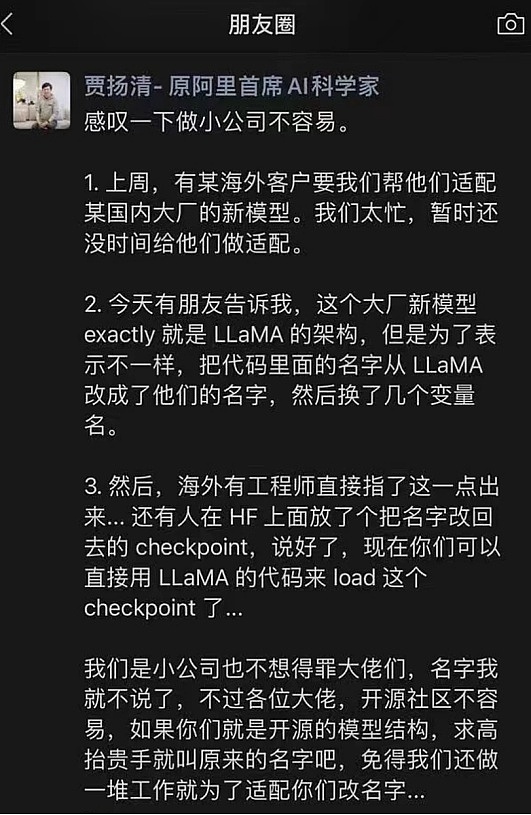
这条朋友圈很快就引起一众吃瓜群众的好奇,可谓是一石激起千层浪。业内外纷纷猜测,虽然没有指名道姓的说破,但贾扬清说的“某大厂”其实就是前不久刚发布了Yi-34B大模型的零一万物。
没错,就是“AI教父”李开复的新作。
作为李开复AI团队的第一个大模型,Yi-34B得名于340亿的参数量,也是基于GPT的架构,且在Hugging Face和C-Eval的两个开源大模型排行榜上都取得了第一的好成绩。然而就在发布后不久,Hugging Face社区就给零一万物留言了,要求其修改大模型张量。理由也很简单:除了两个重命名的张量外,Yi完全使用了Llama的架构。
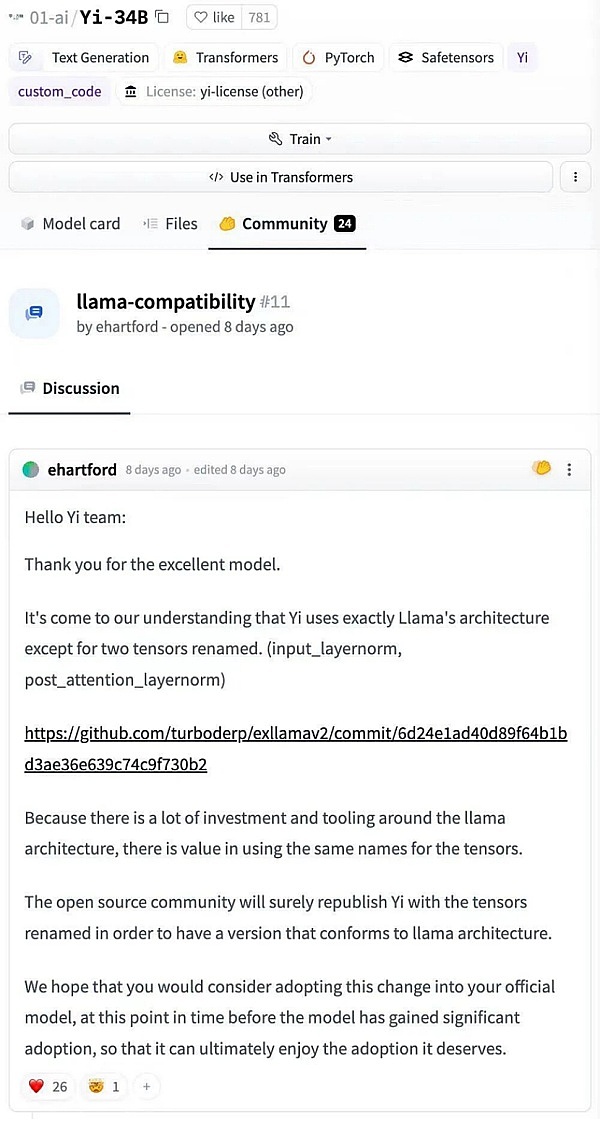
消息一出就引起不少人的驻足围观,嘲讽零一万物的,支持李开复的都大有人在,当然更多的还是在吃瓜。不过综合这几天的消息来看,外界争论的焦点主要有二:1.为什么现在还有套壳的?2.为什么是李开复?
一、关于套壳
国产大模型套壳是个被吐槽已久的现象,真可说是“冰冻三尺,非一日之寒”。比零一万物更早的,今年五月亮相的科大讯飞“星火1.0”,在发布会现场被人问到“你是谁发明的”时,得到的回答“我是OpenAI发明的”,迅速引起轩然大波,对科大讯飞的口诛笔伐也随之而来。但很快科大讯飞就表态,星火之所以这么说是因为他们和OpenAI用的训练数据集大同小异。而根据机器学习与AI科学中的经典理论“垃圾进,垃圾出”,即输出数据的质量与输入数据的质量是成正相关的。如果用错误的、无意义的数据训练大模型,大模型自然也一定会输出错误、无意义的结果。经过半年多的发展,星火现在已经进化到了3.0版本,虽然还是免不了这样那样的非议,但就实际表现来看,它不像是套壳的产品。
前面说过零一万物公司的做法似乎介于“套壳”和“借鉴”之间,但国产大模型套壳也不是最近一两天才有的。三月百度的文心一言首秀后,与之配套的文生图也同样引起广泛质疑,认为其实质上是把汉语机翻成英语,再将单词输入至Stable Diffusion生成了图像。最明显的莫过于“车水马龙”,被机翻成了“car、water、horse、dragon”四个词,之后再以此为提示词生成了如下所示的怪异图片。

尽管百度表示,文心一言完全是百度自研的大模型,文心一言的文生图能力来自文心跨模态大模型ERNIE-ViLG,但外界对此的质疑始终没有打消,直到半年多后的今天依然如故。最明显的一点,车水马龙的本意是“车如流水,马如游龙”,即使要翻译为英语也绝非将四个字一一对照的翻译为car、water、horse、dragon。如果不是套壳,它为什么要符合英语而不按照中文的意思来呢?
当前各家企业基本都有算力、人才和资金方面的缺口,导致一些只想挣快钱的团队也想走捷径。另一个原因同样不能忽视,就是当前大模型创业的时间窗口已经非常紧张了。毕竟有目共睹的,大模型这把火已经烧了近一年,该入局的玩家早已入局,整个行业的格局已经基本形成。

九月时的格局,现在应该更多
事实上,在贾扬清发朋友圈后不久零一万物就做出了回应,他们承认Yi-34B的结构设计的确是基于GPT的成熟结构,借鉴了LLaMA的公开成果,但是这是为了与行业主流保持一致,更有利于适配和迭代。不过外界似乎对此并不买账,因为这种解释涉及一些很重要也很基本的问题:到底该怎样明确地界定“套壳”和“借鉴”?在开源产品的基础上进行修改、调整,究竟算不算一种“套壳”行为?

从技术层面上来说,判断一个项目是“借鉴”还是“套壳”,关键在于评估所做的改进或优化是否具有实质性和原创性。在借鉴的过程中,开发者会在原有大模型的基础上做出显著的增值,例如引入新的数据处理技术、优化算法性能,或者开发基于某个行业或应用的特定功能。同时在借鉴时,开发者通常都会明确指出他们的改动是基于哪款开源大模型,并说明他们所做的改进和创新,这种做法也符合开源社区的原则和精神。相对地,如果改动仅限于浅显的表层,没有提供任何新的技术见解或实质性的性能改进,那就可以被视为套壳。
这么看来,这次零一万物的Yi-34B究竟是借鉴还是套壳?

从目前已有的信息来看,零一万物公司的做法似乎介于“套壳”和“借鉴”之间。他们确实在一定程度上依赖了LLaMA的架构,但也在数据处理、训练方法等方面进行了自己的工作和创新。例如使用了自建的数据管线,从3PB原始数据中精选到3T token的高质量数据,以及在在网络宽度和深度上测试了不同的方法。但同时,这些改进不那么容易通过大模型的架构或代码直观的发现,通常都在大模型的内部,而不是直接体现在大模型的基础架构上。
这么看下来,将零一万物的做法完全归类为“套壳”可能有失公允。但如果就此视为完全独立地“借鉴”同样不妥,原因在于其架构与LLaMA架构的确有很高的相似性。当一个新款大模型在核心架构上,与现有的开源大模型高度相似甚至一致时,即使在其他方面有所创新和改进,也很难被完全视为独立的“借鉴”。
二、为什么要套壳
大厂的地位难以撼动,国外同行又不断推陈出新,留给国内大模型初创企业的时间日益紧张。在市场上同类竞品越来越多的情况下,客户何必偏偏苦守一个研发缓慢,前景又不甚明朗的大模型呢?市场对于快速解决方案的需求迫在眉睫。客户的需求不能等,要的是现在就能用的解决方案,而不是几年后的尽善尽美。迫于如此压力,有点团队选择使用开源大模型作为基础,对其进行部分的改进和定制以适应市场的需求。毕竟即使人财物全部齐备,创新和自研的过程也是漫长且充满不确定性的,“科研的道路上充满了沮丧”是不争的客观事实。同时因为AI领域正在快速发展和变化,市场和技术的不确定性意味着巨大的研发风险。
在三月GPT-4上线后,很多对手都以此为目标,然而殊不知对手可不会原地不动的等着被超越。国内第一个亮相的文心一言,以自己的实际表现说明了何为“刚上台就过时”。在技术飞速发展的时代背景下,许多团队可能比三月的百度更惨,自研的产品甚至连过时的机会都没有。九月底OpenAI推出了DALL·E 3,紧接着就是GPT-4V和语音交互功能,在多模态层面迈出了一大步。而本月初开发者大会的一系列“王炸”更新,相信很多人至今记忆犹新,OpenAI轻描淡写的GPTs,直接扼杀了想在“局部领域”突围的国产大模型。
尽管OpenAI看似强大到无所不能,好在还是有对手的。

对于初创企业来说,在保持技术创新的同时,也要考虑到商业化的可行性和市场的接受度。而有着成熟框架且得到市场广泛认可的开源大模型,无疑成了一种可靠的,可以马上投入使用的方案。并且成熟的开源框架通常有一个庞大的社区支持,这意味着团队在遇到问题时可以获得更多的帮助。同时社区中的其他开发者可能已经解决了一些常见问题,团队可以直接借鉴这些解决方案,避免重复劳动。这么看下来,零一万物的作为似乎又情有可原。
就在贾扬清发朋友圈的同时,网上对零一万物的非议也随之出现,其中不乏尖酸的讽刺,比较有代表性的如“国内要发展高新科技其实很简单,只要美国别封锁就可以了”,以及“套壳羊驼是看得起Meta,OpenAI算老几,我们都不拿正眼看的。”在此既不想黑零一万物也不想洗白,只想说明一下,在当前套壳的国产大模型企业中,也不排除的确有一些有长期技术路线的企业。不过众所周知的,用爱发电是不可能长久的。
白话区块链|同步全球区块链资讯、区块链快讯、区块链新闻
本站所有文章数据来源:金色财经
本站不对内容真实性负责,如需转载请联系原作者
如需删除该文章,请发送本文链接至oem1012@qq.com

