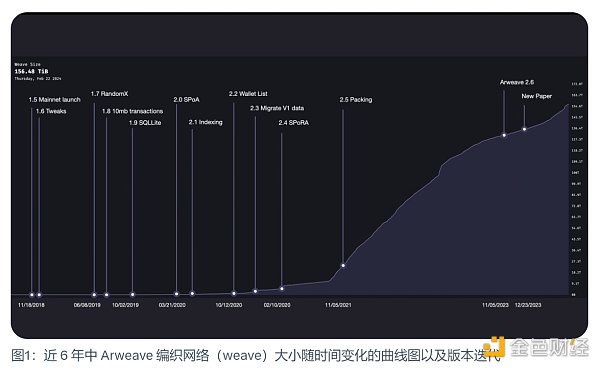
作者:Arweave 来源:X,@ArweaveOasis
Arweave Ecosystem 自 2018 年启动以来,一直被认为是去中心化存储赛道中最具价值的网络之一。但转眼 5 年,由于它的技术主导属性,很多人对 Arweave/AR 是既熟悉又陌生。本文就从回顾 Arweave 自成立以来的技术发展历史入手,以增进大家对 Arweave 的深入理解。
Arweave 在 5 年内共经历了十余次主要的技术升级,其主要迭代的核心目标就是从一个计算主导的挖矿机制转变为由存储主导的挖矿机制。
Arweave 1.5:主网启动
Arweave 主网在 2018 年 11 月 18 日启动。当时的编织网络大小仅有 177 MiB。早期的 Arweave 在某些方面与现在类似,2 分钟的出块时间,每个区块可容纳的上限为 1000 笔。除此之外,更多的是不同的方面,如每笔交易的大小限制仅有 5.8 MiB。并且它使用了一种名为访问证明(Proof of Access)的挖矿机制。
那问题来了,什么是访问证明(PoA)呢?
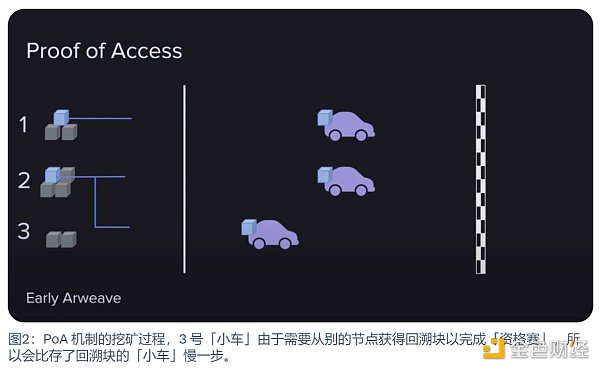
简单说,是为了生成新的区块,矿工必须证明他们可以访问区块链历史中的其他区块。所以访问证明会从链上随机选择一个历史区块,要求矿工将那个历史区块作为一个回溯块(Recall Block)放进他们试图生成的当前区块中。而这将是这个回溯块的完整备份。
当时的想法是矿工们不必存储所有区块,只要他们能证明可以访问这些区块,就可以参与挖矿竞争。(Dmac 在他的视频中用赛车比赛作比喻便于理解,这里引用过来。)
首先这场比赛有一个终点线,这个终点线会随着参与者的数量或挖矿速度而移动,以确保比赛总是在大约两分钟内结束。这就是两分钟区块时间的原因。
其次,这个比赛分为两部分。
·第一部分,可以称为资格赛,矿工们必须证明他们可以访问历史区块。一旦手中有了指定区块,就可以进入决赛。如果矿工没有存储区块,没关系,他们还可以从同行那里访问它,同样可以加入比赛。
·第二部分,相当于资格赛后的决赛,这部分就是纯粹以工作量证明的方式使用哈希计算能力来挖矿,实质上就是消耗能源来计算哈希并最终赢得比赛。
一旦一个矿工越过了终点线,比赛结束,下一场比赛开始。而挖矿奖励都归一个赢家所有,这便使得挖矿变得异常激烈。因此,Arweave 开始快速增长。
Arweave 1.7:RandomX
早期的 Arweave 原理是一个非常简单易懂的机制,但没过多久,研究人员就意识到可能会出现的一个不良结果。即矿工可能会采取一些对网络不利的策略,我们称其为堕落策略。
主要是因为,有些矿工在没有存储指定快速访问区块时,就必须去访问别人的区块,这使得他们比存储了区块的矿工慢了一步,输在了起跑线上。但解决方案也很简单,只要大量堆叠 GPU ,通过大算力、消耗大量能源就能弥补这个缺陷,因此,他们甚至可以超过那些存储区块并保持快速访问的矿工。如果这种策略成为了主流,矿工将不再存储和分享区块,取而代之的是不断优化算力设备,消耗大量能量来获得竞争的胜利。最终结果就会变成网络的实用性大幅下降,数据逐渐变得中心化。这对于存储网络来说,显然是一种堕落的背离。
为了解决这个问题,Arweave 1.7 版本出现了。
这个版本最大的特点是引入了一种叫 RandomX 的机制。它是一个在 GPU 或 ASIC 设备上运行非常困难的哈希公式,这使得矿工们放弃堆叠 GPU 算力,只采用通用 CPU 来参加哈希算力的竞赛。
Arweave 1.8/1.9:10 MiB 交易大小与 SQL lite
对矿工而言,除了证明他们有访问历史区块的能力外,还有更重要的事项需要处理,那就是对用户向 Arweave 发布的交易进行处理。
所有新的用户交易数据都必须被打包进新区块中,这是对一条公链最起码的要求。在 Arweave 网络中,当一个用户向一个矿工提交一条交易数据时,这个矿工不仅会将数据打包进自己即将提交的区块中,还会将它分享给其它矿工,以此让所有矿工都能将这条交易数据打包进各自即将提交的区块中。他们为什么要这样做呢?这里至少有两个原因:
·他们在经济上被激励去这样做,因为每个包含在区块中的交易数据会增加该区块的奖励。矿工们互相分享交易数据,能确保无论谁赢得出块权,都能得到最大的奖励。
·防止网络发展的死亡螺旋。如果用户的交易数据时常会不被打包进区块,那用户就会越来越少,网络就失去了它的价值,矿工的收益也会变少,这是所有人都不愿意看到的。
所以矿工选择以这种互惠互利的方式来最大化自己的利益。但这又带来了数据传输上的一个难题,它成为网络可扩展性的瓶颈。交易越多,区块越大,而 5.8 MiB的交易限制也没有起到作用。因此,Arweave 通过硬分叉,将交易大小增加至 10 MiB,从而获得了一些缓解。
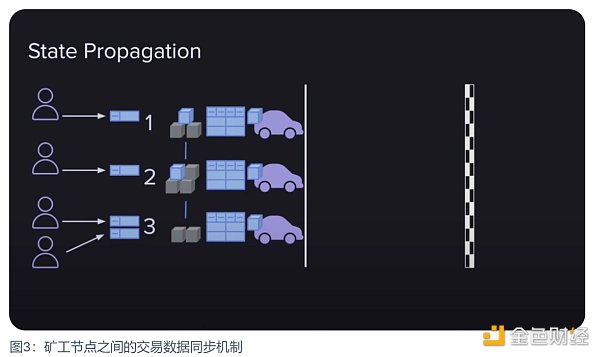
但即便如此,传输瓶颈的问题仍然没有得到解决。Arweave 是一个全球分布的矿工网络,所有矿工都需要同步状态。而且每个矿工的速度连接也都不同,这让网络出现了平均连接速度。为了让该网络每两分钟产生一个新的区块,连接速度就需要足够上传希望在这两分钟内存储的所有数据。如果用户上传的数据超过了网络的平均连接速度,就会导致拥堵,降低网络的效用。这会成为 Arweave 发展的绊脚石。所以,后续 1.9 的更新版本为提高网络的性能使用了 SQL lite 等基础设施。
Arweave 2.0:SPoA
2020 年 3 月,Arweave 2.0 的更新为网络引入了两个重要更新,也因此解除了网络可扩展性的枷锁,并打破了在 Arweave 上存储数据的能力极限。
第一个更新是简洁的证明(Succinct Proof)。这是基于默克尔树加密结构所构建的,它使矿工能够通过提供一个简单的默克尔树化的压缩分支路径,来证明他们存储了一个块中的所有字节。它所带来的改变是,矿工们只需要把一个不到 1 KiB 的简洁证明打包进块中即可,不再需要打包一个可能有 10 GiB 的回溯块。
第二个更新是「格式 2 交易」。这个版本对交易的格式进行了优化,其目的是为了给节点间分享的数据传输块瘦身。相对于「格式 1 交易」需要把交易的头与数据同时加入块中的模式,「格式 2 交易」则允许将交易头和数据分开,也就是在矿工节点之间的块信息数据共享传输中,除回溯块简洁证明之外,所有交易都只需要将交易头加入块中,交易数据可以在竞赛结束后再添加至块中。这将大大降低矿工节点之间同步区块内交易时的传输要求。
这些更新的结果是它创建了比过去更轻、更容易传输的区块,释放了网络中的过剩带宽。矿工们此时会使用这些过剩带宽来传输「格式 2 交易」的数据,因为这些数据在未来将会成为回溯块。因此,可扩展性问题被解决了。
Arweave 2.4:SPoRA
到目前为止,Arweave 网络中的所有问题都解决了吗?答案是显然没有。另一个问题又因新的 SPoA 机制而衍生出来。
与矿工堆叠 GPU 算力类似的挖矿策略又出现了。这次虽然不是 GPU 堆叠的算力中心化问题,但带来一种可能更以计算为中心的主流策略。那就是快速访问存储池的出现。所有历史区块都被存在这些存储池中,当存取证明生成一个随机的回溯块时,它们可以快速生成证明,然后在矿工之间以极快的速度同步。
这虽然看起来没有多大问题,数据在这样的策略中还是可以得到足够多的备份与存储。但问题是这种策略会潜移默化地转变矿工的关注点,矿工不再有动力获得对数据的高速访问,因为现在传输证明变得非常容易且快速,所以他们会将大部分精力投入到工作量证明的哈希运算中,而不是数据存储。这难道不是另一种形式的堕落策略吗?
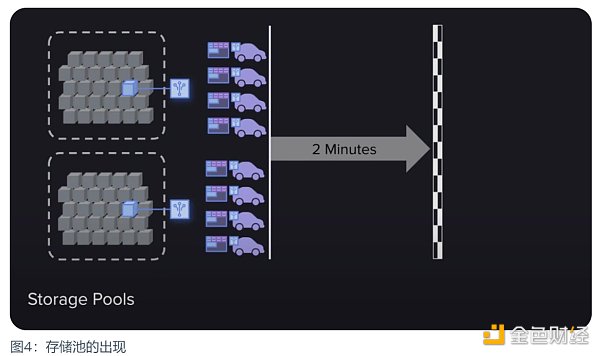
于是,Arweave 在经历了数次功能升级后,如数据索引迭代(Indexing),钱包列表压缩(Wallet List),V1 版交易数据迁移等。终于迎来了又一次大版本的迭代 —— SPoRA,随机访问的简洁证明。
SPoRA 真正将 Arweave 引入到了全新的时代,通过机制迭代让矿工的注意力从哈希计算转到了数据存储上。
那么,随机访问的简洁证明有什么不同呢?
它首先有两个先决条件,
·经过索引的数据集(Indexed Dataset)。得益于 2.1 版本中迭代的 Indexing 功能,它用全局偏移量为编织网络中的每个数据块(Chunk)作了标记,以便每个数据块都可以通过这个全局偏移量来快速访问。这就带来了 SPoRA 的核心机制 —— 数据块的连续检索。 值得提醒的是这里提到的数据块(Chunk)是大文件经过分割后的最小数据单元,其大小为 256 KiB。并不是区块 Block 的概念。
·慢哈希(Slow Hash)。这种哈希用于随机地选出备选数据块(Candidate Chunk)。得益于 1.7 版本引入的 RandomX 算法,矿工无法使用算力堆叠的方式抢跑,只能使用 CPU 进行计算。
基于这两个先决条件,SPoRA 机制有 4 个步骤
第一步,生成一个随机数,并用该随机数与前区块信息通过 RandomX 生成一个慢哈希;
第二步,使用这个慢哈希计算出一个唯一的回溯字节(Recall Byte 即数据块的全局偏移量);
第三步,矿工用这个回溯字节从自己的存储空间中寻找相对应的数据块。如果矿工没有存储该数据块,则返回到第一步重新开始;
第四步,用第一步生成的慢哈希与刚找到的数据块进行一次快哈希;
第五步,如果计算出的哈希结果大于当前的挖矿难度值,则完成块的挖掘与分发。反之则回到第一步重新开始。
所以从这里可以看到,这极大地激励了矿工们尽可能多地将数据存储在能够通过非常快的总线连接到他们的 CPU 的硬盘上,而不是在远在天边的存储池中。完成将挖矿策略从计算导向扭转为存储导向。
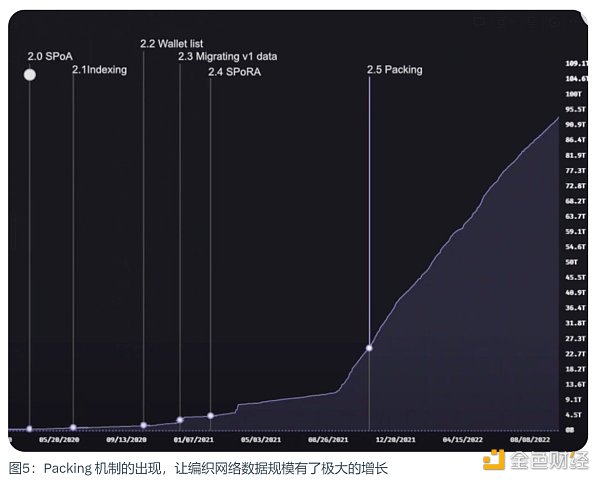
Arweave 2.5:Packing 和数据暴增
SPoRA 让矿工都开始疯狂地存储数据,因为这是改善挖矿效率的最低悬的果实。那接下来发生什么事情呢?
一些聪明的矿工意识到这种机制下的瓶颈实际上是能多快从硬盘驱动器获取数据。从硬盘获取的数据块越多,能计算的简洁证明就越多,能执行的哈希操作就越多,挖到矿的几率就越高。
所以如果当矿工在硬盘驱动器上花费了十倍成本,比如使用了读写速度更快的 SSD 来存储数据,那这位矿工所拥有的哈希能力就会高十倍。当然这也会出现类似 GPU 算力的军备竞赛。比 SSD 更快的存储形式,比如 RAM 驱动器这种更快传输速度的奇特存储形式也会随之出现。不过这完全取决于投入产出比。
现在,矿工能生成哈希的最快速度就是一个 SSD 硬盘的读写速度,这为类似 PoW 模式的能源消耗设定了一个较低的上限,从而更加环保。
这样就完美了吗? 当然还不是。技术人员们认为还可以在此基础上做得更好。
为了能有更大数据量的上传,Arweave 2.5 引入了数据捆绑包机制。这虽然不是一次真正意义上的协议升级,但它一直都是可扩展性计划中的一个重要部分,它让网络的大小得到了爆炸性的增长。因为它突破了我们在开始时谈到的每个区块 1000 笔交易的上限。数据捆绑包只占用了这 1000 笔交易中的一笔而已。这为 Arweave 2.6 打下了基础。
Arweave 2.6
Arweave 2.6 是自 SPoRA 之后的一次重大版本升级。它在此前的基础上又向自己的愿景迈进了一步,让 Arweave 挖矿变得更加低成本以此来促进更加去中心化的矿工分布。
那它具体有什么不同?由于篇幅问题,这里只作简单的介绍,未来会更加具体地专门解读 Arweave 2.6 的机制设计。
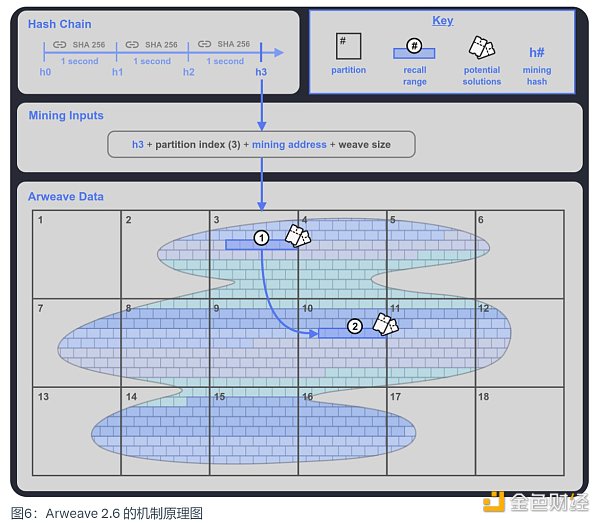
简单理解,Arweave 2.6 就是 SPoRA 的限速版本,它为 SPoRA 引入了一个可以每秒钟滴答一次的可验证加密时钟,我们称其为哈希链(Hash Chain)。
·它每滴答一次就会产生一个挖矿哈希(Mining Hash),
·矿工选择一个他们存储的数据分区的索引来参与挖矿,
·结合这个挖矿哈希与分区索引,可以在矿工选定的已存储数据分区中生成一个回溯范围,这个回溯范围包括了 400 个回溯块,这些就是矿工可以用来挖矿的回溯块。除了这个回溯范围之外,还会再随机在编织网络(Weave)中再生成一个回溯范围 2,如果矿工存储了足够多的数据分区,就能够获得这个范围 2,也就是另外的 400 个回溯块挖矿机会,以此来增加最终胜出的几率。这就很好地激励了矿工去存储足够多的数据分区的副本。
·矿工挨个使用回溯范围内的数据块进行测试,如果结果大于当前给定网络难度即赢得挖矿权利,如果没有满足,则使用下一个数据块测试。
这就意味着每秒钟将会产生的最大哈希数量是固定的,2.6 版本将这个数量控制在普通机械硬盘性能也能处理的范围之内。这让原本基于 SSD 硬盘驱动器最大速度能高达每秒数千或数十万次哈希的能力变成了摆设,只能以每秒几百个哈希的速度与机械硬盘同台竞技。这就好比一辆兰博基尼与一辆丰田普锐斯在一场限速是 60 公里每小时的比赛中竞争,兰博基尼的优势在极大程度上被限制住了。所以,现在对挖矿性能贡献最大的是矿工存储数据集的数量。
以上是 Arweave 在发展历程中的一些重要迭代里程碑。从 PoA 到 SPoA 到 SPoRA 再到 Arweave 2.6 的限速版 SPoRA,始终遵循着原初的愿景。2023 年 12 月 26 日,Arweave 官方又发布了 2.7 版本白皮书,在这些机制的基础上又作了很大调整,将共识机制进化到了 SPoRes 简洁的复制证明。
白话区块链|同步全球区块链资讯、区块链快讯、区块链新闻
本站所有文章数据来源:金色财经
本站不对内容真实性负责,如需转载请联系原作者
如需删除该文章,请发送本文链接至koinfts@gmail.com

